扩散模型(diffusion model)包括两个过程:前向过程(forward process)和反向过程(reverse process)
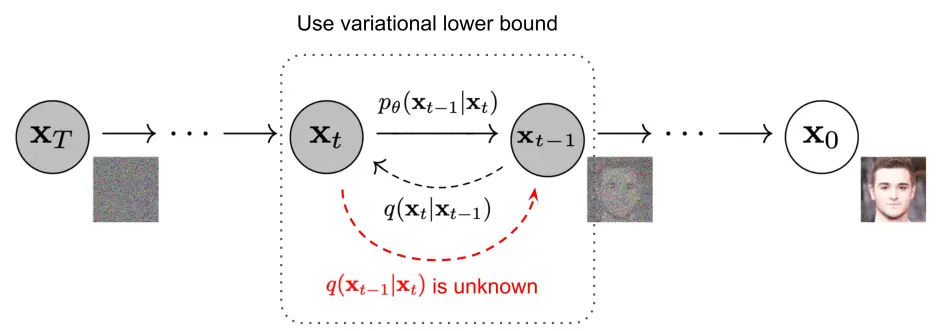
无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain)
- 简单地说,扩散模型的工作原理是通过连续添加高斯噪声来破坏训练数据,然后学习通过反转这种噪声过程来恢复数据。
- 扩散过程,从字面上理解就是,像分子运动一样,一点点改变
- 放到图像里就是,最开始噪声一般的图像,它的像素值一点点改变,或者说叫”运动“,直到最后改变成了有意义的图像

扩散模型由两部分构成:学习过程,推理过程,上面的去噪过程就是推理过程
一、学习过程
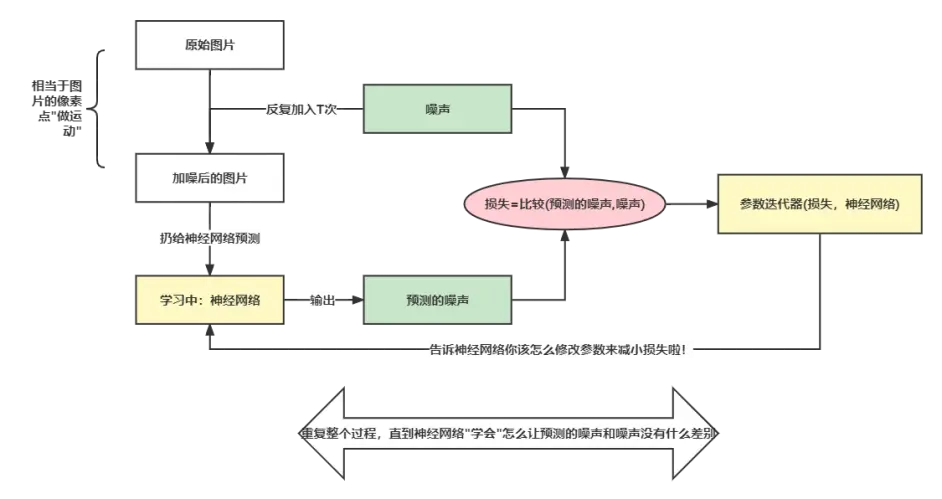
- 首先我们拿到要学习的图片I
- 然后用固定的方法添加一个噪声 N ,并把这个噪声 N 保存下来
- 把噪声 N 扔给我们的神经网络,神经网络会返回一个同尺寸的噪声 PN
- 比较神经网络预测的噪声 PN 和 N 数学尺度上的”差距” ,这个差距我们记为 D
- 把这个差距 D 扔给一个迭代器,它会告诉神经网络应该怎么调整它里面众多的神经参数来缩小 N 和 PN的差距。
- 最后重复不断这个过程,直到 D 的值足够小
二、推理过程
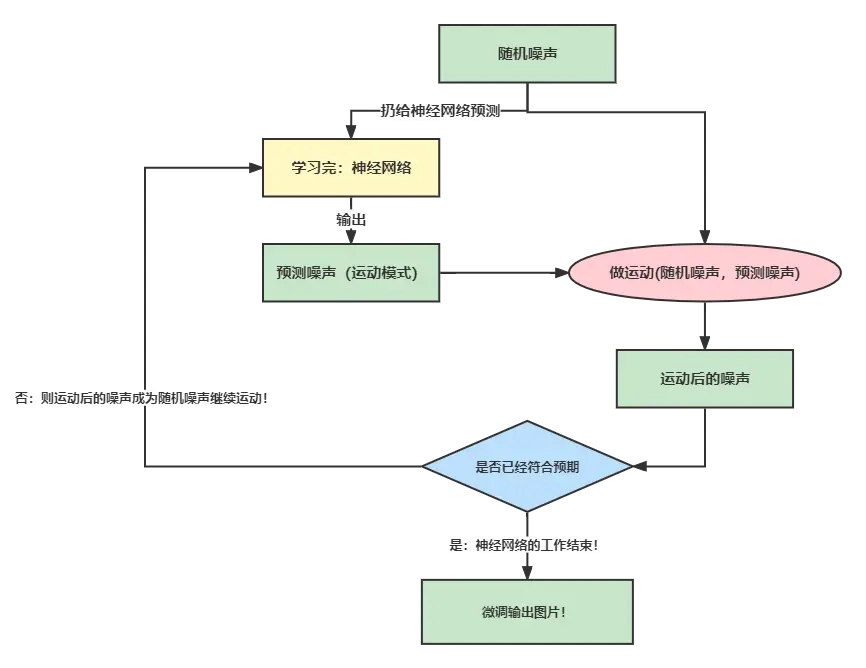
- 首先我们随机生成一个噪声 RD
- 把 RD 喂给已经学习好的 神经网络
- 得到神经网络给出的噪声 PD
- 用原始的噪声 RD根据 PD做运动,得到预测的图片I。这里的运动可以简单理解为原始噪声RD的数值减去预测噪声PD。实际上是做了一些数学变化,而非简单的加减。
- 判断做完运动得到的预测I是否符合我们的预期,如果符合,那就完成预测啦!否则继续6
- 如果运动还不够,则刚刚得到的预测图片I成为新的噪声RD,进行下一轮运动,直到得到我们需要的图片
请注意,我们到目前为止描述的扩散过程在不使用任何文本数据的情况下生成图像。因此,如果我们部署这个模型,它将生成漂亮的图像,但我们无法控制它是金字塔还是猫或其他任何东西的图像
